DANCE RUSH (ダンスラッシュ) は音ゲーではなくダンスゲーなのだという話

音ゲーマーから見たダンスラッシュは譜面の難易度が低くて物足りない。2018/06/25 時点の最高難度 FLOWER ふつう LV 10 でさえも、踏みゲー経験者なら一週間くらいで 95% に届くだろうし、私の観測範囲でも 99% 以上を取ってる人が複数人いる。ぬるい。
- 「レベル11以上が欲しい」
- 「 "むずかしい" が欲しい」
といった声もよく聞く。
だけど、そんな未来はたぶん訪れない。
ダンスゲーとしてなら現時点でも相当ムズイ
ダンスラッシュは確かに音ゲーとしてはぬるいけど、ダンスゲーとして遊んでみると相当ムズイことがわかる。
ここで一つリザルトを紹介したい。
ダンスラ界隈で最も有名であろう一人、あっずさんのツイートなんだけど、ツイート先にある画像(選曲画面)を見てほしい。Butterfly ふつうのハイスコアは 93 %だ。
※1 (主にあっずさん) 本リンクに問題があるならコメントください。削除等致します。Twitter は @stakiran2
この数字を見ると、音ゲー勢は「低くね?」と思うだろう。私も思った。ベテランだから 99% くらい軽く取っているのかと思っていた。
でもこれ、全然低いなんてことはない。むしろ高い。 ダンスゲーとして真面目にダンスしながら遊んでみると、その難しさがわかる。私も最近、正しいランニングマンとスポンジボブを取り入れてみたんだけど、Butterfly は 98% から 93-95% にまで落ちた。これでも毎日数十分、そらで練習している。まだまだ追いつける気がしない。
ランニングマンにせよ、スポンジボブにせよ、ステップとはいえダンスの動きだ。その場でホイホイと習得できるほど甘い技術ではない(出来るのならすごく要領が良い)。ましてダンスラッシュでは、そんな動きに加えて、譜面どおりに踏ませようとするのである。ダンス技術とゲーム要素のミックス。二重にムズイ。
あっずさんを始め、ガチのダンス勢はダンスにこだわっている。私みたいにランニングマンとスポンジボブで自己満しているのではなく、ただのステップにも工夫を凝らしている。難しさは比較にならない。私は未だにランニングマンもスポンジボブもマスターできてないというのに。
ダンスラッシュのムズさは、ダンスゲーとして遊んでみて初めてわかるのだ。
たった 90% で ★★★★★ だという意味
ダンスラッシュのスコアは ★ の個数で格付けされ、1個から5個ある。最高が5個だけど、5個の水準は たった 90% だ。また、EXTRA STAGE の進出条件もやはり 平均 90% である。
音ゲー勢として見たら「90%?低くね?」と思ってしまうけど、ダンスゲーとしてはこのライン、前述のとおり、かなりシビアなのである。
90%。この数字の重みは、音ゲー勢とダンス勢とでは全然異なるということだ。そして最初から 90% に 5 個を割り当ててきたダンスラッシュ開発陣が、ダンスゲーとしての難易度を想定していることは明らかだ。
音ゲーみたくムズイ譜面は登場しないと思う
音ゲー勢は DDR や PIU のような高密度高難度譜面を夢見てしまうが、もう一度言う。そんな未来はたぶん来ない。
- ダンスラッシュはダンスゲームであること
- 現状のレベル 9, 10 のふつう譜面でもダンスゲーとしては十分ムズイこと
- DDR や PIU みたいな密度にしたら物理的にダンスができなくなる(人間の体力では追いつけなくなる)こと
したがって音ゲー的な譜面が来ることはない、と私は思っている。
これまでも音ゲー譜面は FLOWER しか出てない
ここまでのダンスラッシュを振り返ってみると、高難度の音ゲー譜面は FLOWER のみだ。
これまでの配信履歴を挙げてみる。
- 2018/03/23 稼働開始
- 2018/04/27 FLOWER 配信
- 2018/06/08 Crazy Shuffle 配信
これだけだ。2018/06/25 現在で音ゲーレベルの高難度譜面は FLOWER しか出てない。Crazy Shuffle もそこそこ難しいので挙げてみたけど、FLOWER には遠く及ばない。
結果を見ると、三ヶ月が経とうとしているのに FLOWER を超える難易度が登場していないのである。これはダンスラッシュ運営側にも、FLOWER 以上の高難度譜面を出す気がないということではなかろうか。一方で、新曲自体はこれまでに 10 を超えて配信されている。
まとめ
ダンスラッシュは音ゲーではない。ダンスゲーだ。踊るための譜面が重要であって、踏みゲーの音ゲーとしてバカスカ叩くための譜面に用は無い。どころかダンス勢にとって邪魔ですらある。
というわけで高難度譜面を待つ音ゲー勢の皆さん、諦めてダンスしましょう!
関連記事
ダンスラネタは下記別ブログの方でたまに取り上げてます。
GitHub の複数テンプレートから選べる機能 Multiple Issue Templates について仕様を調べてみた
Github で日本語を扱うことが多いので、細かい仕様や挙動を一通り調べておいた。
今回試したリポジトリはこちら
- ディレクトリ構成/ファイル構成
- New Issue 時にどう表示されるか
- .github/ISSUE_TEMPLATE 配下を GitHub に作ってもらう
- まとめ
- (余談1) GitHub ブログのアナウンス
- (余談2) multiple issue templates?
ディレクトリ構成/ファイル構成
ディレクトリ構成:
- .github/ISSUE_TEMPLATE/XXXX.md
XXXX.md の中身:
--- name: <テンプレート名> about: <テンプレートの説明> --- <ここからテンプレート本文> ... ...
XXXX.md のファイル名について:
- New Issue 画面での表示順 に影響する(後述)
New Issue 時にどう表示されるか

↓

.github/ISSUE_TEMPLATE/XXXX.mdの内容がファイル名降順(リポジトリのファイル表示順序と同じ)でズラリと並ぶ- XXXX として日本語ファイル名を使うと、New Issue から作ろうとした時に Ooops! 500 エラーページ が出る
500 エラー:

.github/ISSUE_TEMPLATE 配下を GitHub に作ってもらう
一から作るより楽できるかもしれない。
作り方:
- Settings > Features > Get organized with issue templates > Set up templates ボタン
- 下部の Add template から適当に選び、追加された行に対して Preview and edit ボタンを押して中身を編集、終わったら Close preview ボタンで保存
- Name: テンプレート名
- About: テンプレートの説明
- Template content: テンプレートの中身
日本語が絡む注目すべき仕様:
- テンプレート名(Name)に日本語が含まれる 場合、
-に置換されるテンプレート1.md→-------.md
- ハイフン置換によりファイル名が被った場合、後の方が優先される
テンプレート.mdとほげほげほげ.mdがある場合、------.mdは「ほげほげほげ.md」の方を指す
まとめ
- New Issue 画面での表示順はファイル名降順
- ISSUE_TEMPLATE 配下に日本語ファイル名を置いちゃいけない
(余談1) GitHub ブログのアナウンス
GUI として提供され始めたのは 2018/05/02 っぽい。
しかし機能自体は 2018/01/25 時点では存在していた模様。 /issues/new?template=bugs.md みたいに使いたいテンプレートを URL で指定する感じ。
(余談2) multiple issue templates?
この機能の呼び方だけど、 multiple issue templates でいいのかしら。
We recently helped project maintainers set up multiple issue templates as a way to manage contributions,
AWS の IOPS と I/O クレジットがよくわからなかったので整理した
最近 AWS を触り始めて、EBS を使っているのだが、どうも I/O 速度に制限がかかる仕様があるらしい。調べてみると IOPS やら I/O クレジットやらといった考え方が出てきた。ドキュメントを読んでもわかりづらかったので整理してみた。
- そもそもの前提
- 最初に結論
- I/O クレジットその1: 消費と補充のルール
- I/O クレジットその2: クレジットが枯渇したら
- I/O クレジットその3: IOPS には上限もある
- I/O クレジットその4: IOPS の I/O ってそもそも何?
- 参考
そもそもの前提
AWS のボリュームでは無尽蔵に I/O を発生させることはできず、AWS 側で帯域制限ならぬ I/O 制限が実施されている。
この制限が具体的にいつ、どのように、どれだけ働くのかという仕組みが I/O クレジット という考え方。この時に使う単位が IOPS(I/O per Second) で、読んで字の如く「1秒間のI/O数」を表す。
最初に結論
速度制限について1:
- I/O 回数は I/O クレジット残数(IOPSで表現される)が枯渇すると制限が加えられる
- 制限値は「ボリューム 1 GB あたり 3 IOPS まで」
- この制限は I/O クレジットが回復したら(またクレジットを使い切るまでは)緩和される
速度制限について2:
- ボリュームの種類毎に最大 IOPS が定められており、これを超える速度は出せない
- 例: 汎用 SSD (gp2) だと 10000 IOPS
I/O クレジットの補充/消費ルール:
- [減る] ボリュームで 1 秒間に n 回 I/O を行うと、n [IOPS] が消費される
- [増える] 初期状態では 540 万 IOPS が付与される
- [増える] ボリューム 1GB あたり 3 IOPS が、1 秒毎に補充される
I/O 1回カウントのルール:
- SSD は 256KiB 毎、HDD は 1024KiB 毎の読み書きが 1 I/O になる
- ただしランダムアクセス時は上記の 256 or 1024 毎が適用されない
- 以下 SSD の例:
- 連続アクセスの場合、読み書き量が n [KiB] なら I/O 数は
Ceiling(n/256) - ランダムアクセスの場合、アクセス数が k 回、各アクセスにおける読み書き量が n [KiB] なら I/O 数は
k * Ceiling(n/256)
- 連続アクセスの場合、読み書き量が n [KiB] なら I/O 数は
上記を踏まえて心がけること:
- I/O クレジットが枯渇すると I/O 速度落ちるので、クレジット消費ペース等を事前に計算した上で、必要ボリューム数やサイズ等を設計しましょう
- 上限 IOPS も ボリュームの種類 毎に定まっているので、ユースケースに適した種類を選びましょう
- CloudWatch を使えば I/O クレジットの消費状況をウォッチできます。また必要なら「しきい値を超えた時にアラートを出す」ことも可能のようです(まだ使ってないのでよくわかりません)
以下各ルールや仕様の細かい話が続く。
I/O クレジットその1: 消費と補充のルール
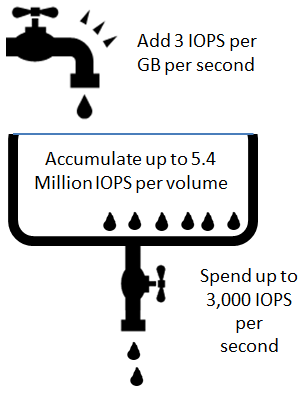
出展: Amazon Web Services ブログ: 【AWS発表】新しいSSDベースのElastic Block Storage
わかりやすそうでよくわからない図だが、要するに IOPS の補充/消費ルール について以下のようなことを言っている。
- [減る] ボリュームで 1 秒間に n 回 I/O を行うと、n IOPS が消費される
- [増える] 初期状態では 540 万 IOPS が付与 される
- [増える] ボリューム 1GB あたり 3 IOPS が、1 秒毎に補充 される
要するに、普通は減る一方の I/O クレジットだが、最初に540万ほど付与される&毎秒少しだが補充されるという話。
I/O クレジットその2: クレジットが枯渇したら
続いて I/O クレジットが枯渇したら(ゼロになったら)どうなるかという話。
結論を言うと ベースラインパフォーマンス にまで I/O 速度が引き落とされる。ベースラインパフォーマンスとは、上記の 1 秒毎に補充されるペースと同じ値。つまり ボリューム 1GB あたり 3 IOPS。
一つ例を挙げる。
例1: 100 GB のボリュームを使っていて I/O クレジットが枯渇した場合
この時、1000 IOPS(秒間1000回のI/O) を発生させようとしても、ベースラインにまで落とされてしまうため、実際は 300 IOPS の速度となる。ベースラインにまで落とされたくなかったら、I/O クレジットが補充されるのを待つしかない。
I/O クレジットその3: IOPS には上限もある
ここでふと疑問が生じる。「じゃあ(I/Oクレジット使い切るまでは)めちゃくちゃバーストさせてもいいの?」と。たとえば 100 万 IOPS(1秒に100回のI/O)を発生させてもいいのか。
結論を言うと 別に構わないがバーストにも上限が定められている。
上限値は ボリュームによって異なる が、一例を挙げると 2018/06/25 時点で以下のようになっている。
| ボリューム種類 | 上限(ボリューム毎) | 上限(インスタンス毎) |
|---|---|---|
| 汎用 SSD (gp2) | 10000[IOPS] | 80000[IOPS] |
| プロビジョンド IOPS SSD (io1) | 32000[IOPS] | 80000[IOPS] |
たとえば「汎用 SSD (gp2)」ボリュームを使った場合、たとえ I/O クレジットが十分であっても 1 ボリュームあたり 10000 IOPS(秒間1万回のI/O)以上の速度を出すことはできない。また、1 インスタンスに 10 個のボリュームを繋いでいたとしても、10 個それぞれで 10000 IOPS を出すことは叶わない(計 80000 IOPS 分までしか出ない)。
I/O クレジットその4: IOPS の I/O ってそもそも何?
IOPS は I/O per Second だと述べたが、そもそもここでいう I/O とは何を示しているのか。何をどうしたら 1 I/O とみなすのか。
詳しい話は I/O の特性とモニタリング - Amazon Elastic Compute Cloud に書いてあるが、要するに
- 「最大サイズ」分の I/O 操作1回分を 1 I/O とする
- 「最大サイズ」はボリューム種類によって異なる
- SSD: 256KiB
- HDD: 1024KiB
- 連続した読み書きはなるべく最大サイズになるまでマージされる
- 例1: SSD で 32 KiB の連続する 7 個のデータを書き込んだ → 1 I/O
- 例2: SSD で 32 KiB の連続する 8 個のデータを書き込んだ → 1 I/O
- 例3: SSD で 32 KiB の連続する 9 個のデータを書き込んだ → 2 I/O
- 連続しない(ランダムな)読み書きはマージされない
- 例1: SSD で 32 KiB のデータをランダムアクセスで 7 個読んだ → 7 I/O
つまり(SSDを例にすると) 256KiB 分の読み書き一つが 1 I/O になる ということ。連続した 1MB のデータなら 4 I/O、1GB のデータなら 4096 I/O、10GB なら 40960 I/O。
仮に 10 GB のデータを 40 分でコピーした場合、コピー元ボリューム(コピー先ボリューム)では 40960 / 60*40 = 40960 / 2400 ≒ 17 [IOPS] 17 IOPS の読み込み(書き込み)操作が発生したことになる。
参考
AWS で AMI イメージを別リージョンにコピーしようとしたら Images with EC2 BillingProduct codes cannot be copied to another AWS account が出た件
原因
AWS の仕様上、別のアカウントから移行してきた AMI イメージを別リージョンに移すことはできない。
参考: AMI のコピー - Amazon Elastic Compute Cloud
制限
billingProduct コードと関連付けられた AMI を別のアカウントから共有した場合、これをコピーすることはできません。 これには Windows AMI、AWS Marketplace の AMI などが含まれます。
対処方法
具体例で説明したい。
まず状況は以下としよう。
- コピー元リージョン: 東京
- コピー先リージョン: シドニー
- (コピーしたい)AMI イメージ: シンガポールから東京に移行してきたもの
この時、AMI イメージをシドニーにコピーするには、以下のようにする。
- (1) コピー元の東京で、AMI イメージからEC2インスタンスを作る
- (2) 1で作ったEC2インスタンスから AMI イメージを作る
- (3) 2で作ったイメージをコピー先のシドニーにコピーする
つまり コピー元リージョンで作ったインスタンス をイメージ化することで、イメージの内部情報(BillingProduct codeと呼ばれるやつ)をコピー元リージョンのものに書き換える、というイメージか。
なぜこんな仕様なの?
これは私の推測だが、billingProduct コードとは要するに AWS が管理する「AMI イメージ単位のライセンス」みたいなもの。Windows AMI や RHEL AMI みたいに OS 側でライセンスが必要なもの、あるいは AWS Marketplace AMI みたいにそもそも有料で販売されているもの等に対して、無闇にコピーされるのを防ぐ仕組み……ではないかと思う。
ソースがあったらどなたか教えてください。。。
AWS で NAT ゲートウェイ作ろうとして Nat Gateway is not available in this availability zone と怒られた件
原因
AWS の仕様で NAT ゲートウェイを作れないアベイラビリティゾーンがある。そのアベイラビリティゾーンで作ろうとした時にこのエラーが出る。
対処方法
NAT ゲートウェイを作れるアベイラビリティゾーンを頑張って当ててください。
「NAT ゲートウェイを作れないアベイラビリティゾーン」って何?
Ans: 具体的にはわからないみたい。
AWS ドキュメントの アベイラビリティーゾーンがサポートされていない (NotAvailableInZone) を見ても
制約のあるアベイラビリティーゾーン
としか表記されてなくて「だからどのゾーンよ?」という話。
ちなみに当方では
- とあるアカウントAで作業していて、
- 東京リージョン + ap-northeast-1a → NG
- 東京リージョン + ap-northeast-1b → OK
という感じだった。
いちいち調べるのはだるいので「このアベイラビリティゾーンが使えません!」というリストが欲しいところではある。
AWS で EC2 インスタンスを別アカウントに移す
普通に AWS がサポートしてた。
手順1: 移行元アカウントでの作業
- EC2 > 移行したいEC2インスタンスを選ぶ > アクション > イメージ > イメージ作成
- イメージが完成したら、
- AMI > イメージパーミッションの変更 にて以下設定を
- Private にする
- 移管先のアカウント番号を指定する
手順2: 移行先アカウントでの作業
- AMI > フィルタを「自己所有」から「プライベート」に変更する
- 移行させた AMI イメージが見えるはずなのでそれを選択 > 作成
あとはいつも EC2 インスタンスを作るみたく各種設定を埋めていけばいい。EBS など基本的な設定は引き継がれているはず。ただし ネットワークインタフェース(特にIP)は引き継がれてない ので手動で変える。
Windows のシステム設定を自動化するための覚え書き
仮想マシンだったり、新しく移行した PC だったり、と Windows セットアップ後の各種システム設定を自動化したい。いちいち手で設定するのはだるい。なんとかできないかと思って調べたことと、現時点での結論。
背景
- コントロールパネル等を手打ちで反映するのがだるすぎる
- スクリプト一発で反映できたら理想だよね
結論
- コマンドで制御できるもの → コマンドの使い方を覚えれば自動化できると思う
- コマンドで制御できないもの → レジストリを直にいじればよいが、どの設定がレジストリのどこに保存されてるか調べないといけないし、レジストリいじっただけでは設定反映されないので微妙
コマンドで制御できないもの
レジストリ に保存されていて、かつ コマンドによる保存をサポートしていない 設定全般。
現時点での結論
- 保存場所(キーとエントリ)はググれば見つかる
- レジストリ操作は
regコマンド、あるいは PowerShell のSet-ItemProperty - 問題
- レジストリいじっただけでは システムに反映されない
反映されない、とは?
たとえば下記フォルダオプションのレジストリにて HideFileExt を 0 から 1(隠しファイルを表示→非表示)に変えたとする。エクスプローラー上ですぐさま反映されるかというと、No である。
反映は エクスプローラー自身が(当該レジストリを)再読込しない限り 行われない。フォルダオプションの画面(コントロールパネル)で OK ボタンを押した時に反映されるのは、エクスプローラーがそういう作りになっているから。
反映させるにはどうしたらいい?
再読込させればいい。
ただし対象アプリ(たいていはエクスプローラー)が再読込のインタフェースを公開していなければ不可能である。せいぜい プロセスをまるごと殺して、また再起動する ことで無理矢理一から読み込ませる程度か。
restart_exlorer.bat
@echo off taskkill /f /IM explorer.exe start "" explorer.exe
ただしこの強引再起動だと「一部のトレイアイコンが表示されなくなる」といった問題が生じる。また、「画面」と「フォルダを開いてるアプリ」全部に再読込処理が走るため重たい。
(参考) レジストリの保存場所の調べ方
たとえばシステムのプロパティ > 詳細設定タブ > パフォーマンスオプション の「パフォーマンスを優先する」のレジストリ保存場所を調べたい場合。
- 1 日本語で「パフォーマンスを優先する レジストリ」などで検索する
- 2 見つからない場合、英語で検索する
- 2-1 英語名を調べる
- パフォーマンスオプション → performance option、これで英語版 Google で画像検索
- 「Adjust for best performance」だとわかる
- 2-2 「adjust for best performance registry」で検索
- How could I disable windows effects through batch - Stack Overflow が見つかった
- 2-1 英語名を調べる
結論: VisualFXSetting=2 が「パフォーマンスを優先する」の意。
Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\VisualEffects] "VisualFXSetting"=dword:00000002
(参考) フォルダオプション
「隠しファイルを表示」「拡張子を表示」「保護されたファイルを表示」の保存場所。
Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\Advanced] "Hidden"=dword:00000001 "HideFileExt"=dword:00000000 "ShowSuperHidden"=dword:00000001
参考: registry - Configure Windows Explorer Folder Options through Powershell - Stack Overflow
コマンドで制御できるもの
レジストリ
reg コマンド。
- reg add/delete/copy で直接操作
- reg save/load/restore で hiv ファイルベースの import/export
- reg import/export で reg ファイルベースの import/export
ちなみに hiv と reg の比較は以下。
- hiv はバイナリファイルだが ACL(権限設定) なども含めて保存する
- reg はテキストファイル
参考: windows - Difference between "reg save" and "reg export"? - Super User
サービス
sc コマンド。
タスクスケジューラ
schtasks コマンド。
環境変数
ローカルなら set、グローバルなら setx で変更可。
ネットワーク(アダプタ)設定
netsh コマンド。
ファイル操作
mkdirフォルダ新規rmdirフォルダ削除delファイル削除moveファイル移動renファイルリネーム
おわりに
本気で自動化するとしたら、
- sc, netsh など各種コマンドの使い方を覚える
- 各種コマンドを使って(自分好みの)設定を行うスクリを書く
- どのシステム設定がレジストリのどこに保存されてるか洗い出す
- レジストリを(自分好みの設定に)いじるスクリを書く
- エクスプローラーを再起動するスクリを書く
- 必須ではない
- 最悪 Windows を再起動すれば反映されるし
これら全部をやらないといけない。気が遠くなるような作業だ。
更新通知手段としての Twitter
Twitter してないのは機会損失だと思うので始めてみた。とりあえず各種サービスの投稿を Twitter にも通知する「通知マン」として動かしてみることに。
はてなブログ投稿 to Twitter
- はてなブログで アカウント設定 > 外部サービス連携
- Twitter にてはてなに権限を与える
するとブログ投稿後の画面にて「Twitterでもシェアする」的なボタンを押せるようになるので、それを押すとツイートされる。
サンプル:
- 記事: http://stakiran.hatenablog.com/entry/2018/06/16/073328
- 連携ツイートサンプル: https://twitter.com/stakiran2/status/1007753060007882753
詳しくは はてなヘルプ を参照。
GitHub でリポジトリ新規 to Twitter
Tweet new repositories from my Github user - IFTTT
IFTTTを使う。
IFTTT に GitHub アカウントを連携させた後、上記レシピ用の設定(アカウント名と Twitter 上に投稿するメッセージの書式)を行う感じ。この時、権限を与えなきゃいけないんだけど、Private Repo まで Full Access を要求してくるのがちょっと怖い(Public だけでよくない?)……。
設定後、テストする。GitHub で適当にリポジトリ作って、このレシピの管理画面で Check Now ボタンを押す。Run 1 times みたいに表示されれば成功。これが Never run だとまだ実行されてない(サーバーが混んでる?)のでしばし待つ。そのうち更新される。
サンプル:
- つくったリポジトリ: https://github.com/stakiran/test_new_repo_to_twitter_with_ifttt
- ツイート: https://twitter.com/stakiran2/status/1007755154991517696
GitHub でスター to Twitter
Post Github star to Twitter - IFTTT
こちらのレシピは特に権限は与えなくてもいい(これが本来あるべき姿だと思う)。
サンプル:
- スターをつけたリポジトリ: https://github.com/stakiran/test_new_repo_to_twitter_with_ifttt/stargazers
- ツイート: https://twitter.com/stakiran2/status/1007757297551073280
Qiita 投稿 to Twitter
Qiita の管理画面で Twitter アカウントを連携するだけで OK。
すると投稿時に「Twitterにも投稿する」チェックボックスが出てくるので、チェックを入れてやればツイートできる。
サンプル:
- Qiitaに投稿した記事: https://qiita.com/sta/items/6d08151fd9b20fa8b319
- ツイート: https://twitter.com/stakiran2/status/1007759838582132736
おわりに
意外と簡単に連携できる(一部はIFTTT使ってるけど)。
VMWare 仮想マシン上で新規作成した Windows Server 2016 に対して最低限行う設定
前提
- 社内環境内で手早く使う用途(なのでセキュリティは度外視)
- フリーソフトは使わない
1. RDP(リモートデスクトップ)接続する
仮想マシンへのアクセスは (vSphere Client からの)コンソールではなく、RDP を使う。そうしないとクリップボードやファイル/フォルダのコピーが行えなくて不便なため。
- コントロールパネル > システムのプロパティ > リモートタブ > リモートデスクトップを許可する
2. 絶対やりたい
- コントロールパネル > フォルダオプション > 拡張子と隠しファイルを表示
- サーバーマネージャ
- 管理 > サーバーマネージャのプロパティ > 自動起動をオフにする
- IEセキュリティ構成 オフ
- Windows Defender オフ
- コントロールパネル > ファイアウォール > オフにする
3. できればやりたい
- 作業ディレクトリは c:\work に
- c:\work をクイックランチに放り込む
- 「ファイル名を指定して実行」を開くバッチ(open_run.bat)を置く
- Internet Explorer
- ツールバー右クリ > 別の行にタブを表示
- ツールバー右クリ > メニューバーを表示
- オプション > ホームページを about:blank に
- ....
open_run.bat
@echo off
start "" explorer Shell:::{2559a1f3-21d7-11d4-bdaf-00c04f60b9f0}
バッチファイルを開くだけで指定した文字列(IDやパスワードなど)をコピーする
Windows で仕事をしていると色んな環境やらアカウントやらの ID/パスワード を使うことになるが、いちいち覚えるのはだるい。かといってテキストに貼り付けておいてコピペするのもだるいし、 そういう情報を管理するフリーソフトは使わせてもらえない ケースがある。特に他所様の PC とか。
そんな時に、バッチファイルを使って簡単にコピーするというアイデアが使える。
※フリーソフトが使えるなら素直に使えばいいと思います
成果物イメージ
- AWS_UserName1.bat というバッチファイルがある
- これを叩くと、AWS アカウント UserName1 のパスワードがコピーされる
このようなバッチファイルを多数作れば、コピーしたい分を叩くだけでパスワードをコピーできるようになる。
つくりかた
例として以下架空の AWS アカウントを例にする。
- ID: UserName1
- Pass: Password123
以下のようなバッチファイルを作る。ファイル名はたとえば AWS_UserName1.bat
@echo off setlocal set id=UserName1 ★ここと set pass=Password123 ★ここを埋める echo ID :%id% echo Pass:%pass% echo %pass%|clip timeout 2
作った後、起動すると、ID とパスワードが黒い画面に表示されるとともに、パスワードがコピーされているはず。
Q: IDをコピーしたい
以下のように修正してください。
echo %pass%|clip ↓ echo %id%|clip
Q: なんかコピーが上手くいきません
バッチファイルの仕様で 記号を含む文字列は上手くコピーされません。
Q: 画面が2秒くらいで閉じるのがだるいのでもっと長くしたい
デフォは2秒になってます。これを10秒に変えたいなら以下のように。
timeout 2 ↓ timeout 10
また、画面を速攻で閉じたい場合は timeout の行を丸々削除しても OK。
Windows 10 のシンクライアント端末を少しでも快適に使うためのカスタマイズ
シンクラ端末はセキュリティの関係上、ほとんどの設定を変更できないようになっているが、それでも多少は変更できるようになっていると思う(会社によるかも)。そのままだと何かと不便なので、できるだけ頑張って快適にしてみる。
- [設定] 「休止状態」を追加する
- [設定] カバーを閉じたときの動作
- [設定] その他電源オプション全般
- [設定] その他コントロールパネル全般
- [運用] 外付けのマウスやキーボードを使う
- [設定] タスクトレイに常駐しているアプリの設定は全部見直す
- [運用] 使ってない時でもたまに起動する
- [設定] IPv6 を切る
- [運用] 通信が遅い環境ではシンクラを使わない
[設定] 「休止状態」を追加する
Windows は起動/終了が遅いので「電源入れっぱ」で使うのが当たり前だが、ノート PC の場合だとそうもいかない(セキュリティ的に電源入れたまま放置が許されない等)。かといってスリープだと2日もしないうちにバッテリーが切れる。
そこで使うのが 「休止状態」。
休止状態なら数日放置してもバッテリーが持つので、次使う時もサクっと短時間で復帰しやすい。
設定方法:
- コントロールパネル
- 電源オプション > 電源ボタンの動作の選択
- 「休止状態」にチェックを入れる
- グレーアウトされてるなら「現在利用可能ではない設定を変更します」から変更できるようにする
[設定] カバーを閉じたときの動作
端末が邪魔な時に、電源を入れたままカバーを閉じることがよくあるが、デフォルトだとスリープに入ったりしてうざいので切っておく。
設定方法は電源オプションから。
[設定] その他電源オプション全般
その他、電源オプションは一通り眺めておいた方が良い。たとえば省エネ設定が強すぎて画面が暗めなのを明るめにするとか。
[設定] その他コントロールパネル全般
そもそもコントロールパネル内は一通り眺めておいた方が良い。キーボードとマウスの設定はよくやる。
[運用] 外付けのマウスやキーボードを使う
シンクラ端末同梱のキーボードやトラックパッドは非常に使いづらいので、別途使い慣れたマウスやキーボードを接続することをオススメする。
特にマウス。私の周囲を見ても、リテラシーや改善に疎い管理職おじさんですら普通にマイマウスを使っているレベル。
[設定] タスクトレイに常駐しているアプリの設定は全部見直す
よくあるのがセキュリティ系ソフトウェアのアップデートやスキャンのスケジュール。毎日だと重たくてやってられないので、業務してない昼休憩や深夜に設定するとか、週一にするとか工夫する。
[運用] 使ってない時でもたまに起動する
Windows Update などアップデート処理を適用するために、シンクラ端末は 使わない場合でもたまに起動しておく のが良い。これをしておかないと、久々に立ち上げた時にアップデート処理が走って「重くて仕事にならない!」事態に。
[設定] IPv6 を切る
通信が重たい場合、IPv6 設定を切ると若干改善が見られることがある。
手順はまとめるのがだるいので こっち を見てください。わかる人向けに要点書くと、
- コントロールパネル
- ネットワークと共有センター
- アクティブになってる通信アダプタのプロパティを開いて、
- ……
- 「インターネットプロトコルバージョン6(TCP/IPv6)」のチェックを外す
Q: なぜ IPv6 を切ると通信が早くなる?
Ans: Windows や DNS サーバーが「まずは IPv6 で通信してみて、ダメなら IPv4 で通信する」みたいな仕組みになっているから。
しかし IPv6 は対応していないサーバーがあったり、レガシーなシステムだと結局 IPv4 しか使ってないケースもあったりするため IPv6 を使う分、処理が遅くなる 現象が起きている。IPv6 を切ると、その遅い部分をカットできるため、早くなるという話。
[運用] 通信が遅い環境ではシンクラを使わない
シンクラは常にサーバー側と通信させることで実現しているので、通信環境が貧弱だと画面描画やキーボード/マウスの反応も遅くなり、業務に差し支える。通信環境が遅い場所ではそもそも利用しないようにする。遅いまま使い続けてもストレスになるだけ。
SSL 証明書、サーバ証明書、ルート証明書、オレオレ証明書……その辺の話を咀嚼してまとめた
SSL 絡みのエラーが起きた時に「何が起きているのか」「どうすればいいのか」を理解し対処できるようになることを目標にしたい。言い換えると、対処法をググっておまじないとして「なんかこうしたら動いた」で解決するのではなく、その背景をちゃんと理解したい。
というわけで、SSL やら証明書やらの話題(特に仕組みや各用語の意味など)について雑多にまとめてみた。
SSL certificates(SSL証明書) とは
SSL認証を行うのに使うファイル。拡張子は .pem だったり .crt だったりする。内容は公開鍵の羅列。
例: GlobalSign Root CA(ルート1) と GlobalSign Root CA(ルート2) を並べた例
-----BEGIN CERTIFICATE----- MIIDdTCCAl2gAwIBAgILBAAAAAABFUtaw5QwDQYJKoZIhvcNAQEFBQAwVzELMAkG A1UEBhMCQkUxGTAXBgNVBAoTEEdsb2JhbFNpZ24gbnYtc2ExEDAOBgNVBAsTB1Jv ... -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- MIIDujCCAqKgAwIBAgILBAAAAAABD4Ym5g0wDQYJKoZIhvcNAQEFBQAwTDEgMB4G A1UECxMXR2xvYmFsU2lnbiBSb290IENBIC0gUjIxEzARBgNVBAoTCkdsb2JhbFNp ... -----END CERTIFICATE-----
参考:
- RSA鍵、証明書のファイルフォーマットについて - Qiita
- pem や crt など拡張子の厳密な意味に詳しい
- pem はエンコーディングの形式(上記の例もこれ)
- crt は証明書(署名付き公開鍵)データそのもので、pem 等の形式で書かれている
CA_BUNDLE とは
ルート証明書 や 中間証明書 をいっしょくたにした SSL 証明書ファイルのこと。
要するに SSL 認証で実際に使う公開鍵を列挙したもの。
CA_BUNDLE を指定する
ブラウザだけ使ってる場合は CA_BUNDLE を意識することはあまりない。元からブラウザに同梱されているし、追加手順が必要な場合(たとえば会社で一度くらいはやらされたことがあるのではなかろうか)も「証明書をインポートする」的な手順で、ブラウザから証明書ファイルをインポートするだけで済む。
問題は一部アプリやコマンドや、もっと低レベルではプログラミングで「HTTPS 通信を行う時に使うライブラリ」を使う時。これらはブラウザが持ってる証明書ファイルを見てくれない。じゃあどうするかというと「この証明書を使え」と我々が指示する必要がある。
- 環境変数にて証明書ファイルのパスを指定する
- curl コマンドは
CURL_CA_BUNDLE環境変数に - openssl コマンドは
SSL_CERT_FILE環境変数に
- curl コマンドは
- ライブラリのインタフェースにて証明書ファイルパスを指定する
- Python の requests ライブラリの GET メソッド
requests.get()はverify引数に
- Python の requests ライブラリの GET メソッド
CA_BUNDLE の取得先
下記 URL から直接ダウンロードする。
公開鍵暗号方式(公開鍵と秘密鍵)
公開鍵暗号方式って何?公開鍵と秘密鍵の違いは?……などなど、SSL認証を知る上で避けて通れないこの暗号方式についてざっくりと解説する。知ってる人は飛ばせばいい。
登場人物
- データ …… 暗号化したいデータ(誰かに見られちゃ困るデータ)
- 公開鍵 …… なんか暗号化で使うやつ1
- 秘密鍵 …… なんか暗号化で使うやつ2
- 変換器 …… データと鍵を受け取って暗号化を行うプログラム
- 暗号化されたデータ …… データを暗号化したもの。見ても意味不明で元のデータは取り出せない。
暗号化のルール
公開鍵暗号のルールを4つほど挙げる。これを頭に入れておく。
ルール1: 公開鍵で暗号化できる
[データ] + [公開鍵] ----> ★変換器★ ----> [公開鍵で暗号化されたデータ]
ルール2: 秘密鍵で暗号化できる
[データ] + [公開鍵] ----> ★変換器★ ----> [秘密鍵で暗号化されたデータ]
ルール3: 「公開鍵で暗号化されたデータ」は秘密鍵で元に戻せる
[公開鍵で暗号化されたデータ] + [秘密鍵] ----> ★変換器★ ----> [データ]
ルール4: 「秘密鍵で暗号化されたデータ」は公開鍵で元に戻せる
[秘密鍵で暗号化されたデータ] + [公開鍵] ----> ★変換器★ ----> [データ]
データを安全にやり取りする方法
上記4つのルールを使うと、二者間でデータを安全にやり取りできる。
例として(IDやパスワードなどデリケートなデータをやり取りする)ウェブサイトを想定しよう。
まず登場人物は二人。
- ウェブサイト見る人
- ウェブサイト
彼らの所持品はこうなっている。
- ウェブサイト
- 秘密鍵(誰にも教えない)
- 公開鍵(一般公開する)
で、ウェブサイト見る人は、ウェブサイトが公開してる公開鍵を入手し、これを使ってデータを暗号化してからウェブサイトに送信する。このデータは 秘密鍵を持つウェブサイト運営元しか元に戻せない ので安全だ。たとえ通信途中で盗聴されたとしても問題無い。
まとめ
つまり公開鍵暗号方式とは、
- 公開鍵で暗号化したデータは秘密鍵でしか元に戻せないよ
という絶対的なルールの下に成立する暗号技術。
Q: そんな都合の良い暗号技術ってホントにあるの?どうやって実現しているの?
Ans: 具体例を挙げると RSA暗号 など
理解するには数学と情報工学の知識が必要。いやはやこんなの考えるなんて先人は凄いですね。
サーバ証明書とルート証明書の関係や仕組み
いまさら聞けない、SSLサーバ証明書とルート証明書の関係.pdf
サーバ証明書って何?ルート証明書って何?違いは?どんな風に動作してるの?……その辺よくわからんかったのでまとめた。上記 PDF が詳しいが、勉強がてら自分の言葉であえてまとめた。
SSLサーバ証明書
- 各ウェブサーバが持ってる「公開鍵と署名」の組データ
- 公開鍵 = 各ウェブサーバが使う公開鍵暗号用の公開鍵
- 署名 = 認証局が発行された「このウェブサーバーさんはこういう身元で信頼できますよ」的な太鼓判データ
- このSSLサーバ証明書は「認証局の秘密鍵」によって暗号化されている
SSLサーバ証明書は「認証局の公開鍵」でしか復号できない。
ルート証明書
- 各クライアントが持ってる「SSLサーバ証明書を復号する」ためのデータ
- 実体は認証局の公開鍵
- クライアント(ブラウザ)はルート証明書を複数所持している
- ルート証明書は(普段はしないが)手作業で追加/削除することもできる
通信手順
- 1 クライアントがサーバーにアクセス
- 2 サーバーは「SSLサーバ証明書」をクライアントに返す
- 3 クライアントは「ルート証明書」を使って「SSLサーバ証明書」を復号し、中身を調べる
- 署名を取り出せなかった or 署名がおかしい → 相手は信用できないため 通信中止(ブラウザだったら警告出すとか)
- 4 クライアントは復号した「公開鍵」を使ってデータを暗号化し、サーバーに送る
- 暗号化したデータは秘密鍵を持つ相手サーバしか復号できないので安全
ざっくり言うとこんな感じ。本当は更に共通鍵をやり取りする手順があるけど割愛。
ルート証明書はどうやって入手&メンテナンスする?
- ブラウザにデフォで組み込まれている
- ブラウザをアップデートするとルート証明書も更新される
オレオレ証明書
オレオレ証明書はなぜ危険か。そもそもオレオレ証明書は何なのか。その辺よくわからなかったのでまとめた。例も二つ交えて、より具体的にイメージできるようにしたつもり。
オレオレ証明書の意義について
- SSL認証という仕組みがある限り、安全でない相手と通信してしまう危険はほとんどない
- SSL認証のせいで、社内で動かしてるサーバーAも「安全じゃないぞ」とブラウザに弾かれてしまう
- この弾かれをてっとり早く解除する方法が、サーバーAのサーバ証明書Cert-A(これがオレオレ証明書)をつくった上でクライアント側にインポートすること
- そうすればブラウザはサーバーAにアクセスする時、(既にインポートされてる)サーバ証明書Cert-Aを使って「サーバーAさんは信頼できる相手ですよ」と判別できるので弾かない
- つまりブラウザ側が持ってる サーバ証明書という「通信先が信用できるかどうかの判断基準」に、オレオレな基準を追加しちゃう ということ
オレオレ証明書に潜む危険について
- 無闇にオレオレ証明書を使ってると「ブラウザに弾かれてアクセスできない」 → 「そいつのサーバ証明書をインポートすればいいんでしょ?」と機械的に判断するようになってしまう
- もし危ないサイトに対して同じことしちゃったらどうする?
- 結局危ないサイトへのアクセスも許しちゃうことになるわけですよ
Q: 主要なサイトを問題無く閲覧できるのはなぜ?サーバ証明書をインポートした覚えはないよ?
Ans: 主要なサイトのサーバ証明書は 最初からブラウザに入っている から
これらサーバ証明書は 多額の献金と厳しい審査をクリアした組織のみ が入手でき、またブラウザへの同梱が認められている。そういう審査を行う第三者組織(認証局)がある。
例1: Amazon の偽サイト Amazan
Amazon と全く同じ見た目の詐欺サイト Amazan があるとして、利用者が Amazan のサーバ証明書を機械的にインポートしたとしたら?
- 利用者が Amazan にアクセスしてもブラウザは何も弾かない
- 利用者は Amazon だと思って普通に id/pass 打ってログインする
- Amazan 運用者(悪者)から見たら id/pass 筒抜け。悪用しまくれる
もし利用者が「ブラウザに弾かれたサイトは使わない」「無闇にサーバ証明書をインポートしない」ことを徹底していたら、(たとえ Amazon と Amazan の違いに気づけなかったとしても)こんな自体は防げていた。もう少し鋭ければ「あれ?あの有名なサイト Amazon なのになんで SSL 認証が通らないんだ?」と疑い、「あ、よく見たら偽サイトじゃん!」と気付けただろう。
例2: Gmail を使いやすくする Web サービス Gmail+
Gmail を本家よりも圧倒的に使いやすくするラッパー的な Web サービス Gmail+ があるとしよう。この Gmail+ は最近誕生したばかりであり、開発したのは身元のよくわからない個人である。しかし見た目も紹介文もしっかりしており、見た感じ信用できそうである。
利用者が Gmail+ を信用して、Gmail+ からのサーバ証明書をインポートしたとしよう。どうなるか。
- 利用者が Gmail+ にアクセスしてもブラウザは何も弾かない
- Gmail+ が「Gmail と連携が必要なので Gmail の id/pass を打ってください」と言ってくる
- 利用者は Gmail+ を信じているので打つ
- 利用者(HTTPSで通信してるから打った内容が他者に漏れる恐れはないよね)
- Gmail+ の運用者、実は悪者だった!
- 入力された id/pass を使って悪用しまくる
もし利用者が「ブラウザに弾かれたサイトは使わない」「無闇にサーバ証明書をインポートしない」ことを徹底していたら、悪用されることはなかった。尤も利用者がこの徹底をすると、悪意のない Web サービスも使えないことになり、悪意無き Web サービス運用者は溜まったものではないが、そこは Web サービス運用者が「信用できるサーバーの一員」として認めてもらう(認証局に認めてもらう)よう手続きする しかない。頑張れ。
Python requests で SSLError が起きて毎回ググってるのでまとめた
Python で REST API を叩く時は requests ライブラリを使うが、最近の REST API は HTTPS をメインに使うようになった。これに伴い SSLError というよくわからんエラーが出るように。
このエラーは何を意味するのか。どう回避すればいいのか。その辺を知るヒントとして、requests 公式ドキュメントを意訳したもの+α をまとめてみた。
- SSL Cert Verification
- Client Side Certificates
- CA Certificates
- Q: 結局 SSLError を逃れるためには要するにどうすればええの?
- おわりに
SSL Cert Verification
Advanced Usage — Requests 2.18.4 documentation
SSL 認証に絡む挙動や使い方。
- requests はウェブブラウザみたくSSL認証(SSL証明書を用いた認証)を行う
- デフォでは SSL 認証は有効になってて、認証にしくじったら SSLError 例外を投げる
SSL 認証の指定は verify 引数にて行う。
- verify 引数が False だと認証を行わない
- verify 引数が True だと認証を行う(デフォルト)
- verify 引数が「認証局によって認証された CA_BUNDLE ファイルパス」だとそれを使って認証を行う
- あるいは
REQUESTS_CA_BUNDLE環境変数に指定してもいい
- あるいは
- verify 引数が「認証局によって認証された CA_BUNDLE ファイル、のあるディレクトリ」だと OpenSSL の c_rehash 関数 と同じ動きで認証を行う
- 要するにディレクトリ中の証明書ファイル達を使う、というやり方もできるということ
Client Side Certificates
Advanced Usage — Requests 2.18.4 documentation
SSL 認証とは話が逸れるが「クライアント認証」についての話。
SSL 認証は「クライアントが、サーバーに対して、"あなたは信頼できる相手なんですよね?"」を知るための仕組みだが、クライアント認証はその逆で「サーバーが、クライアントに対して "あなたは信頼できる利用者なんですよね?"」を知るための仕組み。つまりは相互認証という、より堅固な認証のお話であって、SSL 認証とは関係が無い話題。
CA Certificates
- Advanced Usage — Requests 2.18.4 documentation
- Python requestsライブラリは認証局の証明書をどう管理する? | Developers.IO
- こっちが詳しい
requests が証明書ファイルをどうやって管理しているかという話。
まず昔の話:
- 昔(v2.16以前) は Mozilla が作ってる証明書ファイルをバンドルしていた
- でもこの方法だと、Mozilla 側の更新を取り込めない(requests にバンドルしてる側の証明書ファイルはどんどん古くなっていく)
更新を取り込むにはどうしたらいい?と考えて、requests が取ったのは以下の仕組み。
- 証明書ファイル更新の仕組みを certifi という別パッケージに分離した
- requests は certifi を使って証明書ファイルにゲット&更新している
- 証明書ファイルを更新したい場合、自分で certifi パッケージをアップデートしてね
- コマンドで言うと
pip install -U certifi
- コマンドで言うと
Q: 結局 SSLError を逃れるためには要するにどうすればええの?
解1: verify=False をセットする
てっとり早い方法。
ただしこれは「SSL 認証はしません」というやり方であるため、通信先が本当に信用できる場合以外は使わないこと。もし信用しちゃいけない相手に対して verify=False しちゃうと(もっと言うとその先の HTTPS 通信でプライベートなデータを渡しちゃうと)最悪、通信先の悪者に悪用されちゃう。
解2: verify='SSL証明書のパス' をセットする
SSL証明書、サーバ証明書、ルート証明書、など呼び方は色々あるが、とにかく「SSL認証で使う証明書」を指定する。そうしたら、指定したその証明書の範囲で SSL 認証をしてくれる。
証明書は CA_BUNDLE という「信頼できる証明書のリスト」的なデータを使うのがてっとり早い。もし会社業務などで別途証明書のインポートを指示されてるなら、その証明書も追加してやる。
証明書ファイルは大体 .pem ファイルか .crt ファイル。中身は公開鍵の羅列。
ああ、あと CA_BUNDLE の入手先はたとえば以下。
おわりに
うん、もう迷わない(と思う)。
Windows 7 + Firefox Quantum でスクロールが遅い、マウスジェスチャーが効かない場合にやること
Windows 7 x86 で Firefox v55.0.3 を使っていた。そろそろアップデートしようと思って Quantum に乗り換えてみたところ、問題が多発した。スクロールが遅い、マウスジェスチャーが効かない、ホイールリダイレクトも効かない……。
格闘したことを記しておく。
前提
- Windows 7 x86(32bit環境)
- Firefox Quantum(v60.2)
起きた問題
(2018/11/16 追記) 今日改めて試してみたところ (2) のマウスジェスチャー以外は発生しなかった(バージョンは v63.0.3)。また (2) についてもアドオンの Gesturefy を導入し、かつかざぐるマウス側「Mozilla 系」のジェスチャーを無効化してやることで解決する。
Firefox Quantum(v60.2) 上でかざぐるマウスが動作しない。具体的には以下のとおり。
- (1) Firefox 上での スクロールが遅い(反応に0.5秒くらいタイムラグがある)
- (2) Firefox 上でかざぐるマウスの マウスジェスチャーが効かない
- (3) Firefox 上でかざぐるマウスの ホイールリダイレクト(「タブをホイール回転で切り替える」)が効かない
やったこと
Firefox を v60.2 から v55.0.3 へ ダウングレード した。
やり方は 以前のバージョンの Firefox をインストールするには | Firefox ヘルプ に従う。といっても FTP サーバーから v55.0.3 のインストーラー Firefox Setup 55.0.3.exe を探してダウンロードして、そのまま実行してインストールしてやるだけ。
インストール後、特に問題は起きていない。
原因は?
Firefox v60.2 のウィンドウが特殊なつくりになっている と思われる。そのせいで既存のマウスジェスチャーやらホイールリダイレクトやらが効かないのではないか。実際、以下ソフトでも Firefox v60.2 のウィンドウにだけ効果がなかったので、良い線行っていると思う。
Firefox のどのバージョンからウィンドウが特殊になったのかは不明。もしかしたら Quantum 初期の v58 なら大丈夫かもしれない?どうなんだろう。
余談: Windows 10 なら問題無い?
Firefox 57(Quantum)で動かなくなった「FireGestures」の代替に選ばれたのは、「Foxy Gestures」と往年の名ソフトでした。 | texst.net
上記サイトでは、Windows 10 ではかざぐるマウスが普通に動いたと書いてある。本問題は Windows 7、もっというと 32 bit 環境固有の問題なのかもしれない。